ranking_wheeljack_DATA = pd.DataFrame({'country_name': ['ISRAEL', 'UNITED ARAB EMIRATES','CYPRYUS',
'OMAN','JORDAN','KUWAIT','QATAR','BAHRAIN','SAUDI ARABIA','IRAQ','LEBANON','TURKEY','YEMEN'],
't_employmen_rt' : [0,2,0,0,0,1,4,3,0,0,0,0,0],
'gdp_person' : [0,0,0,1,0,4,3,0,2,0,0,0,0],
'gni' : [0,2,1,0,0,3,4,0,0,0,0,0,0],
'immunization' : [2,0,0,0,0,4,1,3,0,0,0,0,0],
'life_expectancy' : [4,0,3,1,0,0,0,0,0,0,2,0,0],
'sanitation' : [3,0,1,0,0,4,0,0,2,0,0,0,0],
'water' : [4,0,3,0,0,0,1,2,0,0,0,0,0],
'internet_users' : [3,4,0,0,0,0,1,2,0,0,0,0,0],
'mobile_subscription' : [0,3,2,0,0,0,0,1,4,0,0,0,0],
'population' : [0,0,4,0,0,1,2,3,0,0,0,0,0],
'trade' : [0,4,1,0,2,0,0,3,0,0,0,0,0]})
for col in ranking_wheeljack_DATA:
if col =='t_employmen_rt' or col =='gdp_person' or col=='gni' or col=='trade':
ranking_wheeljack_DATA[col]=ranking_wheeljack_DATA[col]*2
elif col=='immunization' or col =='life_expectancy':
ranking_wheeljack_DATA[col]=ranking_wheeljack_DATA[col]*5
elif col=='internet_users' or col =='mobile_subscription':
ranking_wheeljack_DATA[col]= ranking_wheeljack_DATA[col]*4
elif col=='sanitation' or col =='water':
ranking_wheeljack_DATA[col]= ranking_wheeljack_DATA[col]*3
else:
ranking_wheeljack_DATA[col]= ranking_wheeljack_DATA[col]*1
ranking_wheeljack_DATA['Total'] = ranking_wheeljack_DATA.sum(axis=1)
ranking_wheeljack_DATA["Rank"] = ranking_wheeljack_DATA['country_name'].rank()
ranking_wheeljack_DATA.sort_values("Total", ascending = False, inplace = True)
print("Top 5 Wheeljack region countries:")
ranking_wheeljack_DATA['country_name'].head(n=5)
 Figure 1: Arabian Peninsula Region
Figure 1: Arabian Peninsula Region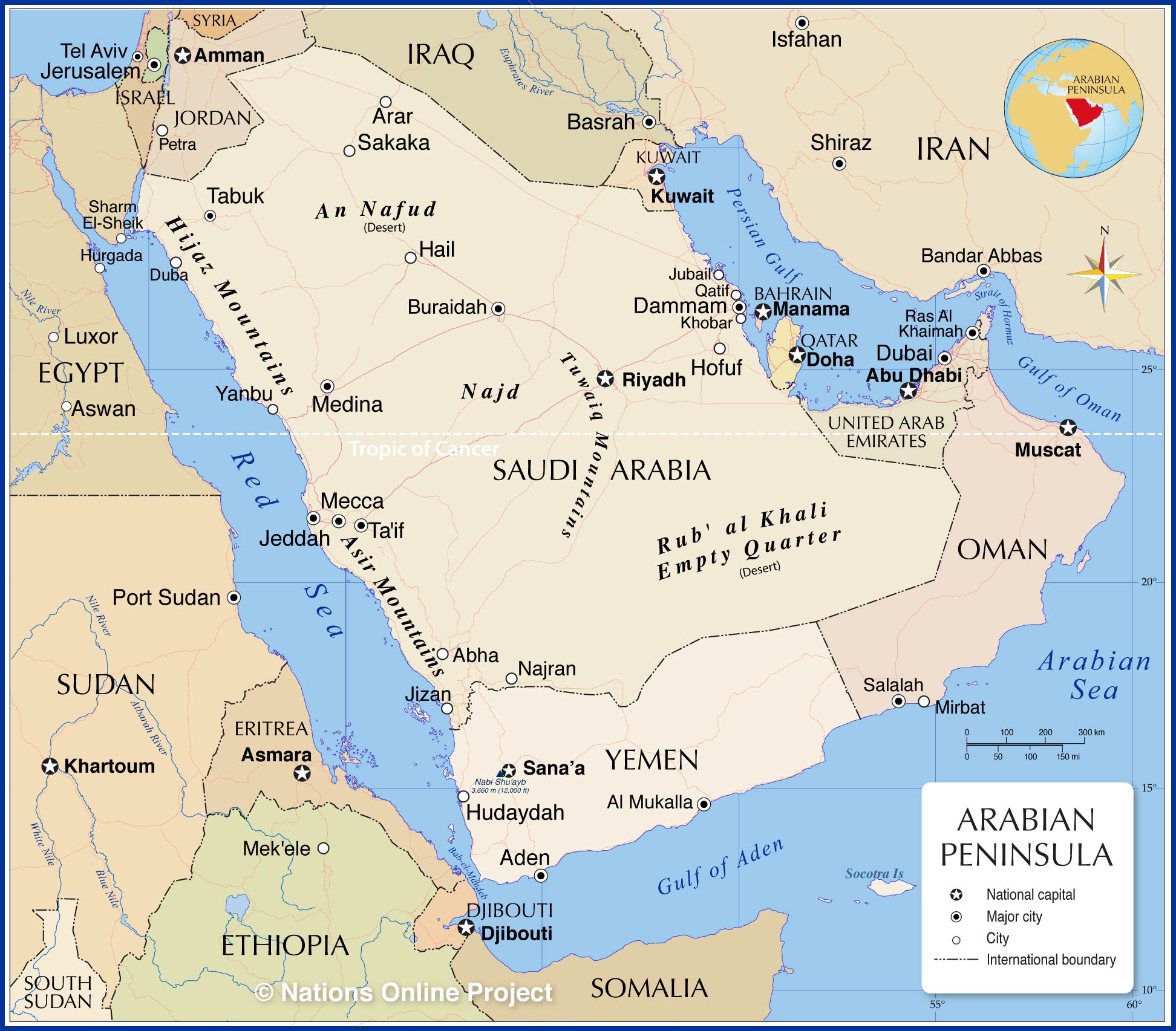 Figure 2: The Map of the Arabian Peninsula
Figure 2: The Map of the Arabian Peninsula









 Figure 3 : Israel's Flag
Figure 3 : Israel's Flag














 Figure 5 : Relief Map of the Arabian Peninsula
Figure 5 : Relief Map of the Arabian Peninsula  Figure 6: the Arabian Peninsula
Figure 6: the Arabian Peninsula